外观
RAG系统评估
RAG评估原理
介绍
评估之所以关键,是因为它回答了RAG开发与应用中的一系列核心问题:
- 对于开发者: 如何量化地追踪、迭代并提升RAG应用的性能?当系统出现“幻觉”或答非所问时,如何快速定位问题根源?
- 对于用户或决策者: 面对两个不同的RAG应用,如何客观地评判孰优孰劣?
评估三元组
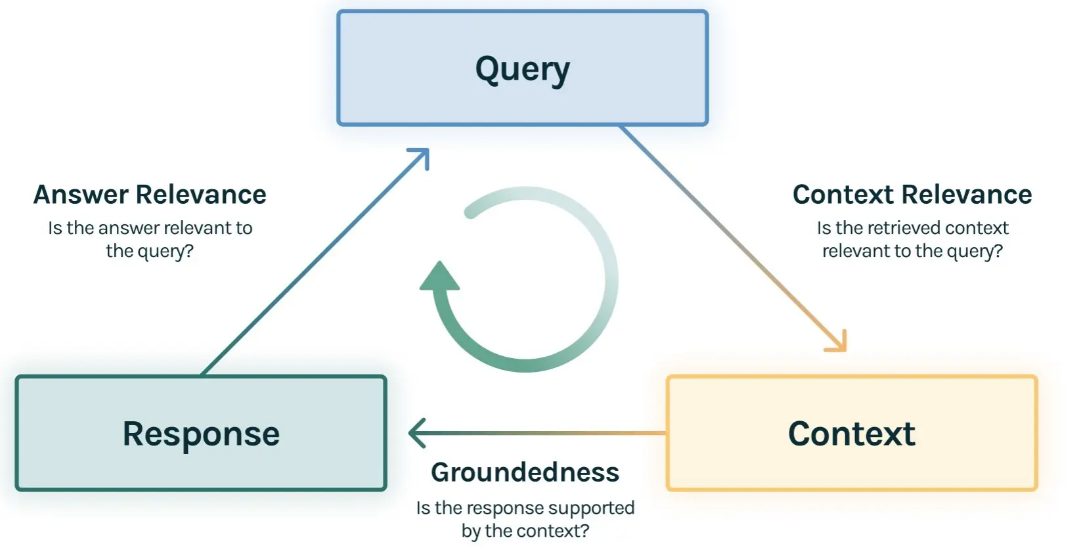
(1)上下文相关性 (Context Relevance)
- 评估目标: 检索器(Retriever)的性能。
- 核心问题: 检索到的上下文内容,是否与用户的查询(Query)高度相关?
- 重要性: 检索是RAG应用在响应用户查询时的第一步。如果检索回来的上下文充满了噪声或无关信息,那么无论后续的生成模型多么强大,都没法做出正确答案。
(2)忠实度 (Faithfulness / Groundedness)
- 评估目标: 生成器的可靠性。
- 核心问题: 生成的答案是否完全基于所提供的上下文信息?
- 重要性: 这个维度主要在于量化LLM的“幻觉”程度。一个高忠实度的回答意味着模型严格遵守了上下文,没有捏造或歪曲事实。如果忠实度得分低,说明LLM在回答时“自由发挥”过度,引入了外部知识或不实信息。
(3)答案相关性 (Answer Relevance)
- 评估目标: 系统的端到端(End-to-End)表现。
- 核心问题: 最终生成的答案是否直接、完整且有效地回答了用户的原始问题?
- 重要性: 这是用户最直观的感受。一个答案可能完全基于上下文(高忠实度),但如果它答非所问,或者只回答了问题的一部分,那么这个答案的相关性就很低。例如,当用户问“法国在哪里,首都是哪里?”,如果答案只是“法国在西欧”,那么虽然忠实度高,但答案相关性很低。
RAG评估过程
可以把评估过程拆解为两个主要环节:检索评估和响应评估。
- 检索评估:检索评估聚焦于RAG三元组中的 上下文相关性
- 响应评估:响应评估覆盖了RAG三元组中的 忠实度 和 答案相关性。此环节通常采用 端到端 的评估范式,因为它直接衡量用户感知的最终输出质量。
RAG评估工具
Ragas
Ragas (RAG Assessment) 是目前业界最流行、功能最全面的开源 RAG 评估框架。它的核心理念是“无需人工标注参考答案(Reference-free)”,利用大语言模型(LLM)本身作为裁判,对 RAG 系统的检索和生成质量进行自动化、多维度的打分。
RAGAS的评估流程
准备数据集:
question:问题,即用户提出的查询。answer:RAG 系统生成的答案contexts:检索到的上下文ground_truth:标准参考答案,对于计算context_recall指标是必需的
运行评估:调用
ragas.evaluate()函数,传入准备好的数据集和需要评估的指标列表。分析结果:获取一个包含各项指标量化分数的评估报告。
核心评估指标
| 指标名称 | 含义 | 评分逻辑 |
|---|---|---|
| Faithfulness (忠实度) | 答案是否完全基于检索到的上下文?有无幻觉? | LLM 检查答案中的每个陈述是否能在上下文中找到依据。 |
| Answer Relevance (答案相关性) | 答案是否直接回答了用户的问题? | LLM 反向生成问题,对比原问题与生成问题的相似度。 |
| Context Precision (上下文精确度) | 相关信息是否排在检索结果的前面? | 衡量相关文档片段在检索列表中的排名位置(越靠前分越高)。 |
| Context Recall (上下文召回率) | 检索到的内容是否包含了回答问题所需的所有信息? | 对比上下文与标准答案(若有)或推导出的必要信息点。 |
| RAGAS Score(综合指标) | 综合得分 | 上述指标的加权平均(通常 Faithfulness 和 Context Recall 权重较高)。 |
LlamaIndex Evaluation
LlamaIndex Evaluation 是深度集成于LlamaIndex框架内的评估模块。对于深度使用 LlamaIndex 框架构建RAG应用的开发者而言,其内置评估模块是无缝集成的首选,提供了一站式的开发与评估体验。
Arize Phoenix
Phoenix (现由Arize维护) 是一个开源的LLM可观测性与评估平台。在RAG评估生态中,它主要扮演生产环境中的可视化分析与故障诊断引擎的角色。它通过捕获LLM应用的轨迹(Traces),提供强大的可视化、切片和聚类分析能力,帮助开发者理解线上真实数据的表现。
RAG评估工具对比
| 工具 | 核心机制 | 独特技术 | 典型应用场景 |
|---|---|---|---|
| RAGAS | LLM驱动评估 | 合成数据生成、无参考评估架构 | 对比不同RAG策略、版本迭代后的性能回归测试 |
| LlamaIndex | 嵌入式评估 | 异步评估引擎、模块化BaseEvaluator | 开发过程中快速验证单个组件或完整管道的效果 |
| Phoenix | 追踪分析型 | 分布式追踪、向量聚类分析算法 | 生产环境监控、Bad Case分析、数据漂移检测 |
实施建议
- 构建“黄金测试集” (Golden Dataset)
- 利用Ragas等工具,从历史日志或核心文档中自动生成覆盖不同难度、不同模态的测试问答对。
- 定期人工抽检修正,确保测试集质量。
- 建立基线 (Baseline) 与 回归测试
- 每次调整检索策略(如更换Embedding模型、调整Chunk大小、引入重排序)后,自动运行测试集,对比各项指标变化。
- 设定阈值,指标下降超过一定比例禁止上线。
- 线上监控与反馈循环
- 部署用户点赞/点踩机制。
- 监控“空检索率”、“长尾查询失败率”。
- 将线上Bad Case自动回流到测试集,持续迭代优化。