外观
两步RAG
两步RAG
介绍
两步RAG 适用于简单、低延迟场景,强制每次查询都执行一次检索 + 一次 LLM 调用。
| 组件 | 类型 | 作用 | 特点 |
|---|---|---|---|
| BM25 | 稀疏检索(关键词匹配) | 初筛召回:快速找出含关键词的候选文档 | 快、准于实体/编号,但无法理解语义 |
| BGE-M3 | 稠密嵌入(Dense Embedding) | 语义召回:通过向量相似度找语义相近内容 | 能处理同义、泛化,但可能漏掉关键词硬信息 |
| BGE-Reranker-v2-M3 | 交叉编码器(Cross-Encoder) | 精排重排序:对 Top-K 候选做两两细粒度打分 | 精度高,但计算慢,不适合全库扫描 |
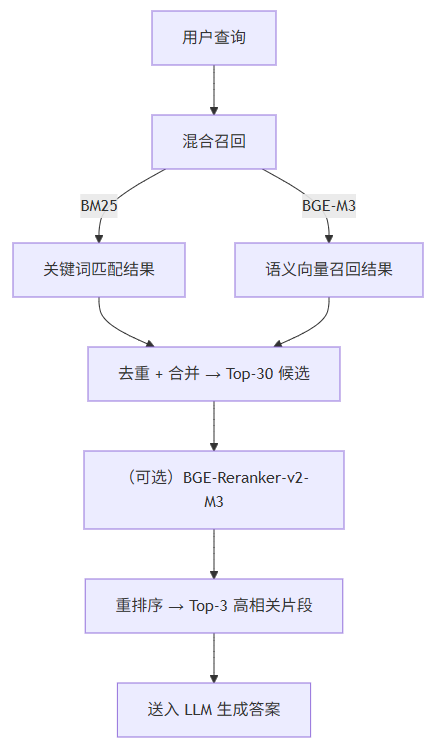
mermaid
graph
Q[用户查询] --> A[混合召回]
A -->|BM25| C1[关键词匹配结果]
A -->|BGE-M3| C2[语义向量召回结果]
C1 & C2 --> D[去重 + 合并 → Top-30 候选]
D --> E[(可选)BGE-Reranker-v2-M3]
E --> F[重排序 → Top-3 高相关片段]
F --> G[送入 LLM 生成答案]参考资料
两步RAG实战
阶段1
Indexing(构建知识库阶段)
python
from langchain.chat_models import init_chat_model
from langchain_ollama import OllamaEmbeddings
from langchain_milvus import Milvus
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.messages import SystemMessage, HumanMessage
# 文档加载器
file_path = "./data/md/热门专业top20.md"
loader = UnstructuredMarkdownLoader(
file_path,
mode="single",
strategy="fast",
)
docs = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs_splits = text_splitter.split_documents(docs)
print(len(docs_splits))
print(type(docs_splits[0]))
print(docs_splits[0])
# 初始化向量模型
embeddings = OllamaEmbeddings(model="bge-m3", base_url="http://192.168.0.129:11434")
# 写入Milvus向量数据库
vector_store = Milvus(
embeddings,
connection_args={"uri": "http://127.0.0.1:19530", "db_name": "default_db"},
collection_name="default_collection",
auto_id=True,
consistency_level="Session",
)
vector_store.add_documents(documents=docs_splits)阶段2
Retrieval & Generation(检索知识库与生成阶段)
python
# 创建LLM模型实例
MODEL = "deepseek-v3.2"
API_KEY = "sk-"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
chat_model = init_chat_model(
model=MODEL, model_provider="openai", api_key=API_KEY, base_url=BASE_URL
)
# 检索上下文
query = "热门专业top20中,前3名有哪些?"
docs = vector_store.similarity_search(query=query, k=3)
serialized = "\n\n".join(
(f"Source:《{doc.metadata.get('original_filename')}》\nContent: {doc.page_content}")
for doc in docs
)
print(serialized)
# 生成并打印回答
context = "\n\n".join([doc.page_content for doc in docs])
messages = [
SystemMessage(
content='你是一个专业助手,请基于以下上下文回答问题。如果不知道,请说"没有找到相关的知识库内容"。'
),
HumanMessage(content=f"上下文:{context}\n\n问题:{query}"),
]
response = chat_model.invoke(messages)
response.pretty_print()输出结果
bash
Source:《热门专业top20.pdf》
Content: 热门专业 top20, 排名分先后
1 、电气工程及其自动化
电气工程及其自动化专业是就业的专业之一,就业率高。
2 、软件工程专业
软件工程专业是就业的专业之一,由于电子产品的普及,这个行业的需求也在增加。软件工程师的工资水平也较高,
有很高的职位和收入。就业前景广阔。
3 、英语
根据就业的专业排名榜,英语专业的就业率高达 90.9% 。这是因为英语是一门广泛使用的国际语言,在各个行业和领
域中都起着重要的作用。
...
Source:《热门专业top20.pdf》
Content: 14 、农林类专业
农林类专业在就业方面表现突出,虽然需求量大,但就业率不高。农林类专业是产业结构的战略性调整,人们对生存
环境的重视,使得农林类专业毕业生就业前景广阔。
15 、护理学专业
护理学专业就业率高,特别是三甲医院和诊所。虽然工作辛苦,但就业上没有问题。
16 、电子商务专业
电子商务专业是就业前景比较不错的 10 个专业之一 , 随着人们手机购物的普及 , 电子商务行业的发展空间是巨大的。
...
================================== Ai Message ==================================
热门专业top20中,前三名依次是:
1. 电气工程及其自动化
2. 软件工程专业
3. 英语