外观
PostgreSQL安装与使用
PostgreSQL
介绍
- 特点:功能强大、支持 JSON、地理空间数据、全文搜索等高级特性。
- 适用场景:需要事务、强一致性、复杂查询的中大型项目。
- 推荐组合:FastAPI + SQLAlchemy(异步) + PostgreSQL +
asyncpg(异步驱动)
版本选择
2026年2月,首选:PostgreSQL 15.15,次选:PostgreSQL 16.11
Docker安装PostgreSQL
安装准备工作
- Windows 上安装 WSL2
- WSL2 上安装 Ubuntu 22.04
- Ubuntu 22.04 上安装Docker
下载镜像
bash
docker pull postgres:16.11运行镜像
bash
# 建立数据目录
mkdir -p /opt/pgdata
docker run -d \
--name my-postgres \
-e POSTGRES_DB=my-rag \
-e POSTGRES_USER=root \
-e POSTGRES_PASSWORD=123456Abcd \
-p 5432:5432 \
-v /opt/pgdata:/var/lib/postgresql/data \
postgres:16.11连接PostgreSQL
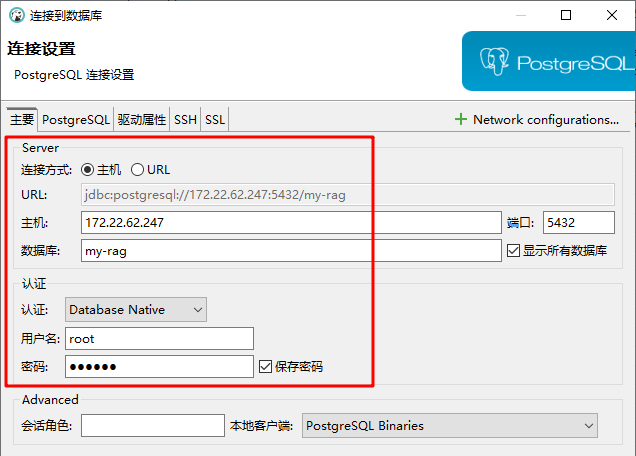
使用DBeaver工具,连接PostgreSQL
- 主机:填写宿主机IP地址
数据库结构的组织层次
- 模式(Schema) 是PostgreSQL 中用于组织数据库对象(如表、视图、索引、函数等)的命名空间。
- 默认情况下,每个新数据库都会自带一个名为
public的 schema。
bash
服务器(Server)
└── 数据库(Database)
└── 模式(Schema)
└── 表(Table)、视图(View)、函数(Function)等数据库对象日期与时间方案一
项目最佳实践建议
- 保持一致性:在整个应用中统一使用UTC时区,在显示时再转换为用户本地时间
- SQLAlchemy配置:在定义模型时明确设置 DateTime(timezone=True),确保类型正确映射
- 在显示时转换:仅在最终向用户展示数据时,才根据用户的本地时区进行转换
- 尽量在一个项目中选择一种主要方式(应用层或数据库层)来生成时间戳,避免混用导致逻辑复杂。
定义模型字段
python
# 应用层设置(Python端生成时间)
created_at: Mapped[datetime] = mapped_column(
DateTime(timezone=True),
default=lambda: datetime.now(timezone.utc), # 确保使用时区感知时间
nullable=False,
comment="创建时间",
)手动更新时间字段
python
my_object.updated_at = datetime.now(timezone.utc)
await db.commit()日期与时间方案二
统一应用层时间(临时方案)
python
created_at: Mapped[datetime] = mapped_column(
DateTime,
default=datetime.now,
nullable=False,
comment="创建时间",
)手动更新时间字段
python
doc.last_processed_at = datetime.now()FastAPI集成
安装与配置
安装
bash
pip install asyncpg配置
python
DB_USER: str = "root"
DB_PASSWORD: str = "your_password"
DB_HOST: str = "127.0.0.1"
DB_PORT: int = 5432
DB_NAME: str = "my-rag"
ASYNC_DATABASE_URL: str = f"postgresql+asyncpg://{self.DB_USER}:{self.DB_PASSWORD}@{self.DB_HOST}:{self.DB_PORT}/{self.DB_NAME}"获取 DB Session
python
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession, async_sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, Session
from typing import AsyncGenerator, Generator
from .settings import settings
# 创建异步引擎
async_engine = create_async_engine(
url=ASYNC_DATABASE_URL,
echo=False, # 是否打印执行的 SQL 语句
pool_size=10, # 连接池大小
max_overflow=20, # 最大溢出连接数
)
# 创建异步会话
async_session = async_sessionmaker(
bind=async_engine, # 绑定异步数据库引擎
class_=AsyncSession, # 使用异步会话
expire_on_commit=False, # 在事务提交后不会使对象过期
)
async def get_db() -> AsyncGenerator[AsyncSession, None]:
"""依赖项:获取数据库会话"""
async with async_session() as session:
try:
yield session # 返回数据库会话
await session.commit()
except Exception as e:
await session.rollback()
raise e
finally:
await session.close()使用
示例
python
from typing import List
from fastapi import APIRouter, File, UploadFile, Response, Depends, Query
from sqlalchemy.ext.asyncio import AsyncSession
from urllib.parse import quote
from app.config.db_config import get_db
from app.config.response_config import SuccessResponse
from app.config.exception_config import BusinessException
from .crud import (
get_document_list_by_kb_id_crud,
get_document_crud,
)
from .schema import DocumentResponseSchema, BatchUploadResponse
from .service import DocumentService
router = APIRouter(prefix="/document", tags=["文档管理"])
@router.get(
"/{document_id}",
summary="获取文档详情",
response_model=SuccessResponse[DocumentResponseSchema],
)
async def get_document_detail(document_id: int, db: AsyncSession = Depends(get_db)):
"""
根据document_id获取文档详情
"""
document = await get_document_crud(db, document_id)
if not document:
raise BusinessException(code=404, msg="文档记录不存在")
return SuccessResponse(msg="获取文档详情成功", data=document)