外观
LangChain重排模型
重排模型
交叉编码器
Cross-Encoder(交叉编码器) 是一种用于判断两个文本之间语义相关性的神经网络架构,特别适用于精排(re-ranking)、语义匹配、问答对评分等任务。
| 方法 | 架构 | 特点 |
|---|---|---|
| Bi-Encoder(双编码器) | 分别编码 query 和 document → 计算向量相似度 | ✅ 快速,可预计算文档嵌入 ❌ 无法建模细粒度交互(如词对齐) |
| Cross-Encoder(交叉编码器) | 将 query 和 document 拼接后一起输入模型 | ✅ 建模深度语义交互,精度高 ❌ 无法预计算,推理慢 |
RAG 标准流程:Bi-Encoder 召回 + Cross-Encoder 重排
重排
重排(Re-ranking)通常是指对检索到的文档或搜索结果按照相关性进行重新排序,以提升后续生成步骤(如问答、摘要等)的质量。
为什么需要重排:向量数据库(如 Milvus )返回的“score”是向量相似度(如余弦相似度),属于 bi-encoder 的粗排结果,而 Reranker 是 cross-encoder 的精排,两者在相关性判断能力上有本质差距。
- 相似度高 ≠ 语义相关(可能只是主题相近但内容无关)。
- 无法理解 query 和 doc 之间的逻辑关系(如否定、条件、因果);
重排模型推荐
说明:重排需要更多的计算资源
| 嵌入模型(Embedding) | 重排模型(Reranker) | 适用场景说明 |
|---|---|---|
BAAI/bge-m3 | BAAI/bge-reranker-v2-m3 | 多语言、混合检索(dense + sparse)场景;支持关键词+语义联合召回,适合高精度企业知识库,尤其含中英混合内容。 |
BAAI/bge-large-zh-v1.5 | BAAI/bge-reranker-large | 纯中文、高精度 dense 检索场景;模型成熟稳定,在中文任务上表现优异,资源消耗低于 bge-m3,适合对延迟或成本敏感的中文专用系统。 |
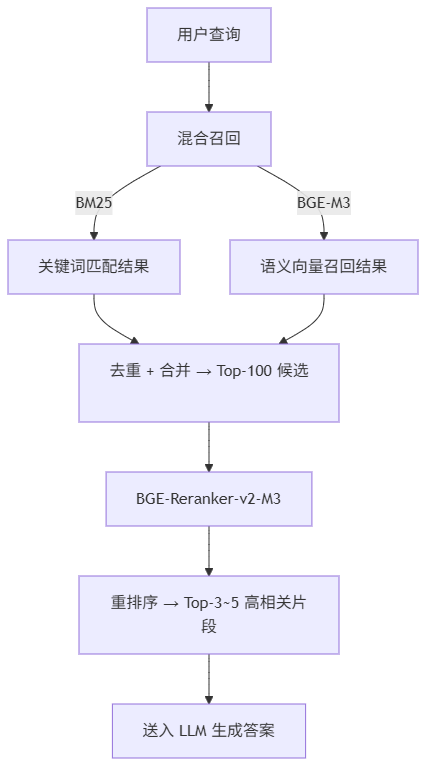
重排方案设计
流水线设计
- 召回阶段(Retrieval):
- 同时用 BM25 和 BGE-M3 混合检索,从知识库召回候选(如各取 50 条,合并去重后得 80 条)。
- 目的:兼顾关键词精确性与语义泛化能力。
- 重排序阶段(Reranking):
- 将合并后的 Top-K(如 K=50)送入 BGE-Reranker-v2-M3。
- 模型对每个
(query, doc)对联合编码,输出精细相关性分数。 - 最终选出 Top-3~5 作为 LLM 上下文,显著降低幻觉风险。
实战Xinference重排服务
准备工作
通过Docker安装Xinference
参考文档:《Xinference安装与使用》
运行模型
可以通过访问
http://<IP>:9997/ui来使用 UIhttp://<IP>:9997/docs来查看 API 文档。
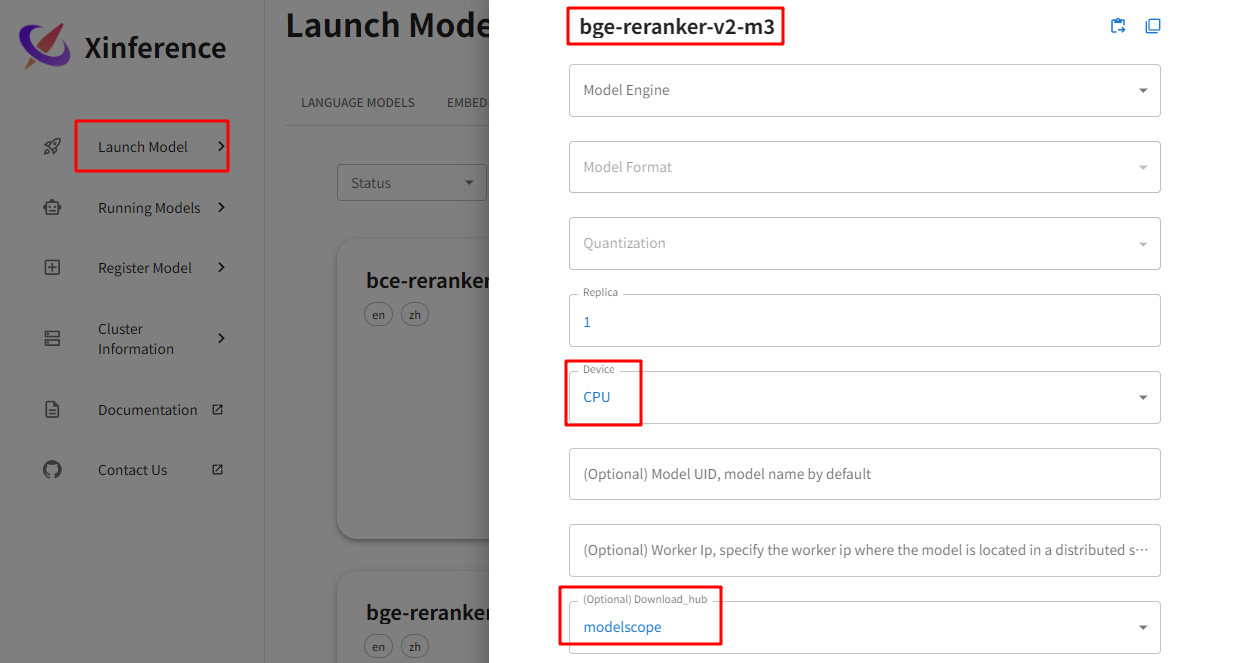
运行模型:登录Xinference界面,Launch Model -- RERAN MODELS -- bge-reranker-v2-m3
curl调用
查看已加载的模型
shell
curl http://127.0.0.1:9997/v1/models调用示例
shell
curl -X 'POST' \
'http://127.0.0.1:9997/v1/rerank' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "bge-reranker-v2-m3",
"query": "你是谁?",
"documents": [
"你是一名乐于助人的AI助手",
"你的名字叫张三"
]
}'SDK调用
安装xinference的client
shell
pip install xinference-client调用示例
python
from xinference_client import RESTfulClient as Client
client = Client("http://172.22.62.247:9997")
model = client.get_model("bge-reranker-v2-m3")
query = "A man is eating pasta."
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
]
print(model.rerank(corpus, query, top_n=4))输出结果:按相关性降序排列
python
{
"id": "af92dad2-fa87-11f0-b1b0-1ae55abc0a13",
"results": [
{"index": 0, "relevance_score": 0.999574601650238, "document": None},
{"index": 1, "relevance_score": 0.0781479924917221, "document": None},
{"index": 3, "relevance_score": 1.770071503415238e-05, "document": None},
{"index": 2, "relevance_score": 1.6375377526856028e-05, "document": None},
],
"meta": {
"api_version": None,
"billed_units": None,
"tokens": None,
"warnings": None,
},
}实战ModelScope重排服务
TODO
(不推荐)实战ST重排服务
sentence-transformers
sentence-transformers 是一个基于 PyTorch 和 Hugging Face Transformers 的 开源 Python 库,专门用于高效生成句子、段落或文本的高质量向量嵌入(embeddings)。核心目标是简化语义文本表示的学习与应用。
sentence-transformers是构建语义理解、检索、RAG 系统的基石库。- 它让开发者只需几行代码就能使用最先进的文本嵌入和重排模型,特别适合与 LangChain、LlamaIndex、Qdrant、Weaviate 等 RAG 组件集成。
- 如果在用 BGE-M3 或 BGE-Reranker,本质上就是在使用
sentence-transformers提供的能力。
安装与示例
安装依赖
shell
pip install sentence-transformers -i https://mirrors.aliyun.com/pypi/simple --trusted-host=mirrors.aliyun.com使用 BGE Reranker 进行本地重排
- 这段代码会主动下载 bge-reranker 模型,会自动从 Hugging Face 下载
BAAI/bge-reranker-v2-m3模型(约 1GB+) - 下载可能失败
python
from sentence_transformers import CrossEncoder
from typing import List, Tuple
class BGELocalReranker:
def __init__(self, model_name: str = "BAAI/bge-reranker-v2-m3", top_n: int = 5, device: str = "cuda"):
self.model = CrossEncoder(model_name, device=device)
self.top_n = top_n
def rerank(self, query: str, documents: List[str]) -> List[Tuple[str, float]]:
# 构造 (query, doc) 对
pairs = [(query, doc) for doc in documents]
# 获取相关性分数
scores = self.model.predict(pairs, batch_size=32, convert_to_tensor=False)
# 打包并排序
scored_docs = list(zip(documents, scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:self.top_n]
# 示例使用
if __name__ == "__main__":
reranker = BGELocalReranker(device="cuda" if torch.cuda.is_available() else "cpu")
query = "量子计算的基本原理是什么?"
docs = [
"量子计算利用量子比特的叠加和纠缠特性进行并行计算。",
"巴黎是法国的首都,拥有埃菲尔铁塔。",
"量子比特可以同时处于 0 和 1 的叠加态,这是经典比特不具备的。",
"牛顿力学适用于宏观低速物体的运动描述。"
]
results = reranker.rerank(query, docs)
for i, (doc, score) in enumerate(results, 1):
print(f"{i}. Score: {score:.4f} | {doc}")sentence-transformers torch langchain faiss-cpu # 或 faiss-gpu