外观
Milvus基础
向量数据库
在 Milvus 中,数据库(Database) 是一个逻辑上的数据组织单元,位于集合(Collection)之上。
数据库基本操作
python
from pymilvus import MilvusClient
client = MilvusClient(uri="http://127.0.0.1:19530")
# 创建数据库
client.create_database(db_name="my_db")
# 切换到该数据库
client.use_database(db_name="my_db")
# 在 my_db 中创建集合(后续操作自动作用于该数据库)
client.create_collection(collection_name="my_collection", ...)
# 查看所有数据库
print(client.list_databases()) # ['default', 'my_db']向量集合
介绍
在 Milvus 中,集合(Collection) 是向量数据的基本组织单元,类似于关系型数据库中的“表(Table)”。集合是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
- 下图显示了一个有 8 列和 6 个实体的 集合。
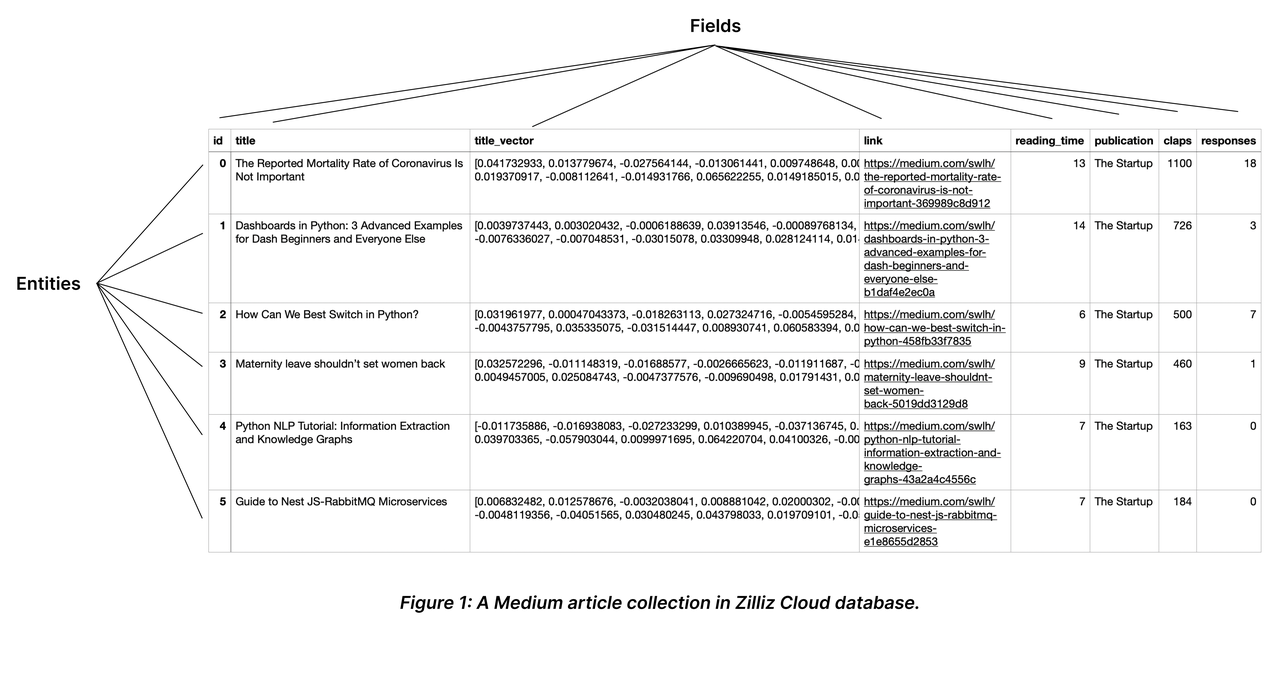
集合与字段
- 集合 (Collection):存储数据的容器。
- 字段 (Field):集合中的列。
- 主键字段 (Primary Key):必须有一个主键(通常命名为
id),用于唯一标识每一条数据。 - 向量字段 (Vector Field):必须有一个专门存储向量数据的字段(例如
embedding)。 - 标量字段 (Scalar Fields):可选,用于存储文本、数字等元数据(例如
title,price)。
- 主键字段 (Primary Key):必须有一个主键(通常命名为
创建集合Schema
创建集合通常需要两个步骤:定义 Schema 和 创建集合对象。
定义 Schema:集合的结构
- 指定字段名称、数据类型(如
INT64,FLOAT_VECTOR) - 关键点:必须指定
dim(向量维度) - 当
auto_id=True时- 插入数据时,Milvus 会自动为每条数据生成内部 ID
- 数据库中存储的
vector_store_ids可能不是 Milvus 内部自动生成的 ID
python
from pymilvus import DataType, MilvusClient
# 创建 Schema
schema = MilvusClient.create_schema(enable_dynamic_field=True)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True,
description="主键自增ID",
)
schema.add_field(
field_name="vector",
datatype=DataType.FLOAT_VECTOR,
dim=1024,
description="向量数据",
)
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=65535,
description="文本数据",
)
schema.add_field(
field_name="source",
datatype=DataType.VARCHAR,
max_length=1024,
description="数据源",
)设置集合索引参数
索引是 Milvus 高效搜索的核心。没有索引,搜索会非常慢。
向量字段:必须为其创建索引。你需要同时指定:
index_type: 索引类型,新手可以直接用"AUTOINDEX",Milvus 会自动选择最适合的算法。metric_type: 度量类型,用于计算向量间的相似度。L2: 欧氏距离,值越小越相似。IP(Inner Product): 内积/点积,值越大越相似(常用于归一化后的向量)。COSINE: 余弦相似度,值越大越相似。
标量字段:如果你经常需要根据某个标量字段(如 category)来过滤搜索结果,那么也应该为它创建索引(例如 STL_SORT),这能极大加速过滤过程。
python
# 设置索引参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(field_name="id", index_type="AUTOINDEX")
index_params.add_index(
field_name="vector", index_type="AUTOINDEX", metric_type="COSINE"
)说明:
- 度量类型匹配:确保
metric_type与你生成向量时使用的相似度计算方式一致。
实例化集合
使用定义好的 Schema 在 Milvus 中实例化一个集合。
python
client = MilvusClient(uri="http://localhost:19530")
client.create_collection(
collection_name="customized_setup_1",
schema=schema,
index_params=index_params
)
res = client.get_load_state(
collection_name="customized_setup_1"
)
print(res)集合其它操作
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://127.0.0.1:19530")
# 切换到该数据库
client.use_database(db_name="my_db")
# 查看集合加载状态
res = client.get_load_state(collection_name="my_collection")
print(res)
# 列出所有集合
res = client.list_collections()
print(res)
# 查看集合详细信息
res = client.describe_collection(
collection_name="quick_setup"
)
print(res)
# 删除集合
client.drop_collection(collection_name="my_collection")集合加载
加载集合是在集合中进行相似性搜索和查询的前提。加载 Collections 时,Milvus 会将索引文件和所有字段的原始数据加载到内存中,以便快速响应搜索和查询。在载入 Collections 后插入的实体会自动编入索引并载入。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.load_collection(
collection_name="my_collection"
)
res = client.get_load_state(
collection_name="my_collection"
)
print(res) # "state": "<LoadState: Loaded>"向量集合高级参数
一致性级别consistency_level
在 Milvus 中,consistency_level(一致性级别)是一个非常重要的参数,它决定了读操作(如搜索、查询)在多大程度上能看到最新的写入数据。这个参数直接影响系统的数据一致性与读写性能/可用性之间的权衡。
| 整数值 | 枚举常量(推荐使用) | 一致性级别名称 | 中文含义 |
|---|---|---|---|
| 0 | ConsistencyLevel.Strong | Strong | 强一致性 |
| 1 | ConsistencyLevel.Session | Session | 会话一致性 |
| 2 | ConsistencyLevel.Bounded | Bounded | 有界一致性 |
| 3 | ConsistencyLevel.Eventually | Eventually | 最终一致性 |
| 4 | ConsistencyLevel.Customized | Customized | 自定义一致性 |
如何选择
| 需求 | 推荐一致性级别 |
|---|---|
| 必须立即看到自己刚写入的数据(如聊天、编辑) | Session (1) |
| 可以容忍短暂延迟,追求更高性能和吞吐 | Bounded (2) |
| 所有用户都必须看到完全一致的数据(金融交易) | Strong (0) |
| 对一致性完全不敏感,只要最终能查到就行 | Eventually (3) |
补充说明
- 在 Milvus 2.2+ 版本中,默认的一致性级别是
Bounded (2)。 Bounded级别在大多数 AI 应用(如 RAG、语义搜索)中是最佳平衡点:既避免了强一致性的性能开销,又不会让用户长时间看不到结果。
python
client.create_collection(
collection_name="customized_setup_6",
schema=schema,
consistency_level="Bounded",
)参考资料:Milvus 一致性级别
度量类型metric_type
Milvus 的度量类型(Metric Types)是指用于衡量向量之间相似性或距离的计算方法。选择合适的度量方式对向量检索、聚类和分类等任务的性能有显著影响。
常用相似性度量:欧氏距离 (L2)、内积 (IP)、余弦相似度 (COSINE)
| 度量类型 | 相似性距离值的特征 | 相似性距离值范围 |
|---|---|---|
L2 | 值越小表示相似度越高。 | [0, ∞) |
IP | 值越大,表示相似度越高。 | [-1, 1] |
COSINE | 数值越大,表示相似度越高。 | [-1, 1] |
应用场景
- 使用 L2(欧氏距离) 的场景:向量本身具有物理意义的绝对坐标(如图像像素、传感器数据)。
- 使用 COSINE(余弦相似度) 的场景:向量表示语义方向而非绝对大小(如文本嵌入、推荐系统用户/物品向量)。
- 使用 IP(内积) 的场景:IP 常作为 COSINE 的高效替代(前提是数据已归一化)。若未归一化,慎用 IP!
参考资料:Milvus 度量类型
索引类型index_type
在 Milvus 中,index_type(索引类型) 是指为向量字段创建的向量索引结构类型,用于加速近似最近邻搜索(ANN, Approximate Nearest Neighbor)。不同的 index_type 适用于不同规模、维度、数据分布和查询需求的场景。
| 索引类型 | 适用向量类型 | 是否支持动态插入 | 是否支持 GPU | 特点 |
|---|---|---|---|---|
| FLAT | 所有(FLOAT/BINARY/SPARSE 等) | ✅ | ✅ | 暴力搜索,100% 精确,无索引构建开销 |
| IVF_FLAT | FLOAT / BINARY | ✅(需先建索引) | ✅ | 基于聚类的倒排索引,精度高,速度较快 |
| IVF_SQ8 | FLOAT | ✅ | ✅ | 对 IVF_FLAT 的量化压缩(每个维度用 8-bit 存储),节省内存 |
| IVF_PQ | FLOAT | ✅ | ✅ | 乘积量化(PQ),大幅压缩内存,适合高维数据 |
| HNSW | FLOAT / SPARSE_FLOAT | ✅ | ❌(CPU only) | 图结构索引,高召回率,低延迟,内存占用较高 |
| DISKANN | FLOAT | ✅(Milvus 2.3+) | ❌ | 基于 SSD 的图索引,适合超大规模(十亿级)向量 |
| SCANN | FLOAT | ✅(部分版本) | ❌ | Google 提出的高效 ANN 算法,结合量化与图搜索 |
| BIN_IVF_FLAT | BINARY_VECTOR | ✅ | ✅ | 二值向量专用的 IVF 索引 |
| AUTOINDEX | FLOAT | ✅ | ✅ | Milvus 自动选择最优索引(基于数据规模等) |
如何选择
| 数据规模 | 维度 | 查询要求 | 推荐索引 |
|---|---|---|---|
| < 10k | 任意 | 高精度 | FLAT |
| 10k – 1M | < 256 | 低延迟、高召回 | HNSW |
| 10k – 10M | 256–1024 | 平衡内存与速度 | IVF_FLAT 或 IVF_SQ8 |
| > 10M | 高维(>512) | 内存敏感 | IVF_PQ |
| > 100M | 任意 | 超大规模、SSD 可用 | DISKANN |
| 不确定 | — | 自动优化 | AUTOINDEX |
说明:
- 索引必须在插入数据后、执行搜索前创建(除非使用
FLAT)。 - 修改索引需先 drop 再重建。
AUTOINDEX在 Milvus Cloud 或较新版本中可用,会根据数据自动选择IVF_FLAT、HNSW等。- 二值向量(
BINARY_VECTOR)只能使用BIN_FLAT或BIN_IVF_FLAT。
参考资料:Milvus 索引
排错
DataNotMatchException
报错信息
shell
pymilvus.exceptions.DataNotMatchException: <DataNotMatchException: (code=1, message=Insert missed an field `producer` to collection without set nullable==true or set default_value)>
(decorators.py:221)
Failed to insert batch starting at entity: 1/13. First entity data: {'pk': '41258d07-ee15-4d6f-8857-66a063adbf61', 'text': '陕西师范大学2024年分专业录情况\n\n年份 省市 类别 科类 专业名称 录取人数 最高分 最低分 平均分 控制线 2024 陕西 公费师范生 理工\\物理类
数学与应用数学(国家公费师范生) 34 645 619 625.4 475 2024 陕西 公费师范生 理工\\物理类 英语(国家公费师范生) 4 631 618 623.8 475 2024 陕西 公费师范生 理工\\物理类 物理学(国家公费师范生) 60 627 605 611.8 475 2024 陕西 公费师范生 理工\\物理类 化学(国家公
费师范生) 55 635 603 610.5 475 2024 陕西 公费师范生 理工\\物理类 生物科学(国家公费师范生) 51 619 602 607.3 475\n\n陕西师范大学2024年分专业录情况', 'vector': '[-0.06054746, 0.01869538, -0.03117842, -0.022429377, 0.011095588, 0.0077479198, -0.020592848, 0.01760907, 0.026978241, 0.037383925]... (truncated, total len: 1024)', 'source': 'uploads\\陕西师范大学.md'}
<DataNotMatchException: (code=1, message=Insert missed an field `producer` to collection without set nullable==true or set default_value)>原因分析
- Milvus集合模式(Schema)中定义了一个名为
producer的字段,但在实际插入的数据中缺少了这个字段,而该字段没有被设置为可空(nullable)或提供默认值(default_value)
解释方案
- 方案一:修改集合模式(推荐)
python
from pymilvus import FieldSchema, CollectionSchema, DataType
# 修改字段定义,添加 nullable=True
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="producer", dtype=DataType.VARCHAR, max_length=256, nullable=True) # 设置为可空
]
schema = CollectionSchema(fields, description="文档集合")- 方案二:在插入数据中包含缺失字段
python
# 在准备插入数据时,确保包含producer字段
chunks_with_producer = []
for chunk in chunks:
chunk.metadata["producer"] = "default_producer" # 或者从文档中提取相关信息
chunks_with_producer.append(chunk)
# 然后使用包含完整字段的数据进行插入
ids = await vector_store.aadd_documents(documents=chunks_with_producer, ids=uuids)