外观
LangChain短期记忆
LangChain 短期记忆
介绍
LangChain 的短期记忆(Short-term Memory) 是指在单个对话线程(thread)中,用于保存和管理交互历史(如用户消息、AI 回复、工具调用等)的机制。
- 线程(Thread)与会话隔离:每个对话被组织为一个 thread,不同 thread 之间的短期记忆彼此隔离,确保多用户或多任务场景下的状态独立。
- 以消息列表为核心:短期记忆主要体现为
messages列表,这个列表会随着对话进行不断增长。 - 状态由 AgentState 管理:可通过继承
AgentState添加自定义字段(如user_id,preferences等),实现更丰富的上下文记忆。 - 持久化依赖 Checkpointer:短期记忆通过 Checkpointer 实现线程状态的持久化(内存或数据库)
LangChain 的短期记忆是一个基于线程、可扩展、可持久化的会话状态管理系统。
实战示例
创建带短期记忆的智能体:使用内存作为检查点
python
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain.messages import HumanMessage, AIMessage
from langchain.chat_models import init_chat_model
MODEL = "deepseek-v3.2"
API_KEY = "sk-"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 创建模型实例
model = init_chat_model(
model=MODEL, model_provider="openai", api_key=API_KEY, base_url=BASE_URL
)
# 创建智能体
agent = create_agent(
model,
checkpointer=InMemorySaver(),
)
# 创建一个会话ID
thread_id = "1000"
response = agent.invoke(
{"messages": [HumanMessage("广东工业大学是211吗?回答是与否")]},
config={"configurable": {"thread_id": thread_id}},
)
# print(type(response))
# print(response)
response = agent.invoke(
{"messages": [HumanMessage("是985吗?回答是与否")]},
config={"configurable": {"thread_id": thread_id}},
)
print(response)输出结果示例
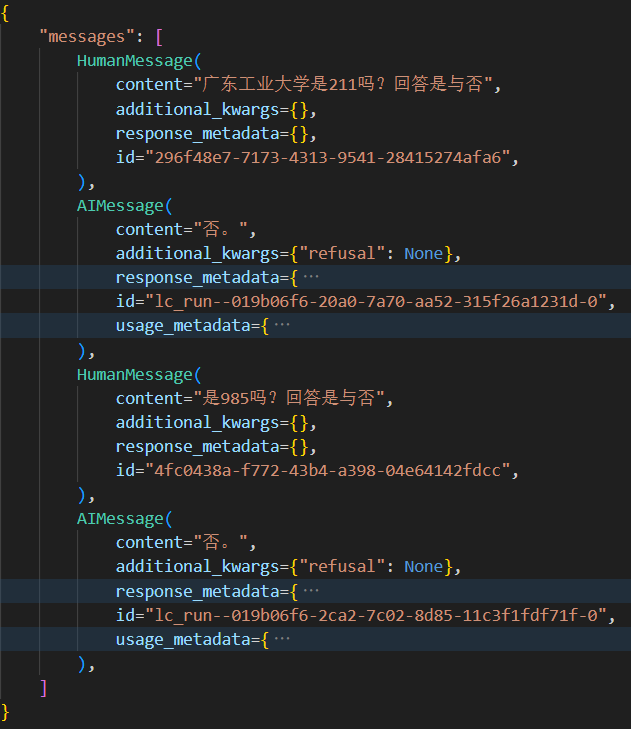
使用MySQL持久化
使用MySQL数据库,持久化保存会话消息列表。参考资料
准备:
- 版本: MySQL >= 8.0.19
- 设置数据库排序规则:选择
utf8mb4_0900_ai_ci(MySQL 8.0+推荐)
安装
shell
# pymysql 驱动
pip install -U langgraph-checkpoint-mysql[pymysql] -i https://mirrors.aliyun.com/pypi/simple --trusted-host=mirrors.aliyun.com
# aiomysql 驱动
pip install -U langgraph-checkpoint-mysql[aiomysql] -i https://mirrors.aliyun.com/pypi/simple --trusted-host=mirrors.aliyun.com
# asyncmy 驱动
pip install -U langgraph-checkpoint-mysql[asyncmy] -i https://mirrors.aliyun.com/pypi/simple --trusted-host=mirrors.aliyun.com使用MySQL 进行持久化
python
from langgraph.checkpoint.mysql.pymysql import PyMySQLSaver
# 创建一个MySQL持久化存储器
DB_URI = "mysql://root:123456@localhost:3306/my-fastapi"
with PyMySQLSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 第1次运行时,请调用此方法创建表
agent = create_agent(model, checkpointer=checkpointer)
# 创建一个会话ID
thread_id = "1000"
response = agent.invoke(
{"messages": [{"role": "user", "content": "广东工业大学是211吗?回答是与否"}]},
{"configurable": {"thread_id": thread_id}},
)
# print(response)
response = agent.invoke(
{"messages": [{"role": "user", "content": "是985吗?回答是与否"}]},
{"configurable": {"thread_id": thread_id}},
)
print(response)定制记忆字段
默认使用 AgentState 模式,可以扩展添加其他字段
python
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
class CustomAgentState(AgentState):
user_id: str
preferences: dict
agent = create_agent(
"gpt-5",
tools=[get_user_info],
state_schema=CustomAgentState,
checkpointer=InMemorySaver(),
)
# Custom state can be passed in invoke
result = agent.invoke(
{
"messages": [{"role": "user", "content": "Hello"}],
"user_id": "user_123",
"preferences": {"theme": "dark"}
},
{"configurable": {"thread_id": "1"}})参考资料
短期记忆策略
长对话的挑战
LLM 的上下文窗口有限,长期累积的 messages 可能导致:超出 token 限制、性能下降、注意力分散等。LangChain 提供短期记忆主流策略
- 裁剪消息:移除前N条或后N条消息
- 删除消息:永久删除消息
- 消息摘要:将历史记录中的早期消息进行总结,并用摘要替换
- 自定义策略:如消息过滤
Trim Messages(裁剪)
在每次调用 LLM 前,通过 trim_messages 中间件裁剪历史消息,只保留第1条和最后3条。
- 根据原列表
messages的长度是否为偶数,动态截取列表末尾的 3 个或 4 个元素,最终把截取结果赋值给新变量recent_messages,全程不会修改原列表messages。
python
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""Keep only the last few messages to fit context window."""
messages = state["messages"]
if len(messages) <= 3:
return None # No changes needed
first_msg = messages[0]
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
*new_messages
]
}
agent = create_agent(
your_model_here,
tools=your_tools_here,
middleware=[trim_messages],
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
"""
================================== Ai Message ==================================
Your name is Bob. You told me that earlier.
If you'd like me to call you a nickname or use a different name, just say the word.
"""Delete Messages(删除)
- 使用
RemoveMessage(id=...)从状态中永久移除旧消息。 - 可在
post_model_hook中实现自动清理。
python
from langchain_core.messages import RemoveMessage
def delete_old_messages(state):
if len(state["messages"]) > 5:
return {"messages": [RemoveMessage(id=m.id) for m in state["messages"][:2]]}Summarize Messages(摘要)
- 使用
SummarizationNode将早期对话压缩成摘要,保留语义信息。 - 需要额外字段(如
context: dict[str, RunningSummary])存储摘要。
python
summarization_node = SummarizationNode(
model=ChatOpenAI(model="gpt-4o-mini"),
max_tokens=384,
max_summary_tokens=128,
output_messages_key="llm_input_messages"
)OpenAI 短期记忆
消息列表
OpenAI 通过传入历史消息列表,实现短期记忆
python
from openai import OpenAI
MODEL = "deepseek-v3.2"
API_KEY = "sk-"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 创建OpenAI API客户端
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# 调用模型
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "你是一个AI助手,回答问题简洁"},
{"role": "user", "content": "张三有100元"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "李四有300元"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "张三和李四一共有多少元"},
],
stream=True, # 是否流式返回结果
)
# 处理结果
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)输出结果
bash
张三和李四的钱加起来是:
100元 + 300元 = **400元**