外观
LangChain嵌入模型
嵌入模型
嵌入模型
LangChain 中的 Embedding models(嵌入模型) 是用于将原始文本(如句子、段落等)转换为固定长度的稠密向量(embeddings) 的组件。这些向量能够捕捉文本的语义信息,使得语义相近的文本在向量空间中距离更近,从而支持语义搜索、相似性匹配、RAG(检索增强生成) 等下游任务。
核心作用
- 将用户查询(query)编码为向量
- 将文档(documents)编码为向量
- 支持后续的向量存储(VectorStore) 和 相似性检索
LangChain 为所有嵌入模型提供了一个标准化接口,定义在 langchain_core.embeddings.Embeddings 抽象基类中,主要包含两个方法:
| 方法 | 功能 |
|---|---|
embed_documents(texts: List[str]) → List[List[float]] | 批量嵌入多个文档 |
embed_query(text: str) → List[float] | 嵌入单个查询 |
嵌入模型选型
开源与闭源嵌入模型对比
| 模型 / 服务 | 向量维度 | 语言 | MTEB 分数 | 长文本 | 优势 | 适用场景 |
|---|---|---|---|---|---|---|
| OpenAI text-embedding-3-large | 3072 | 多语言 | 85.2 | 8k | 精度高、多语言强 | 企业级 RAG、全球化 |
| OpenAI text-embedding-3-small | 1536 | 多语言 | 80.9 | 8k | 成本低、速度快 | 原型 / 中小规模 |
| BAAI bge-m3 | 1024 | 多语言 | 85.0+ | 8k | 稠密 + 稀疏 + 多向量 | 中文 / 跨语言、混合检索 |
| BAAI bge-large-zh-v1.5 | 1024 | 中文 | 84.0+ | 512 | 中文优化、检索导向 | 中文 RAG、垂直领域 |
BGE系列嵌入模型对比
- 对于大多数中国企业级RAG系统,如果业务聚焦国内,文档以中文为主且长度可控,BGE-large-zh-v1.5 是风险更低、性能经过充分验证的稳健选择。
- 如果你的企业处于国际化进程中,或特定业务领域(如法律科技、跨境研究、法律合同分析、学术论文检索)天然涉及多语言和长文档,那么 BGE-M3 所提供的“三多”能力(多语言、多功能、多粒度)将是构建下一代智能检索系统的强大基石
- 在决策前,强烈建议使用业务实际数据的一小部分,对两个模型进行并行的POC测试,以实测的召回率、准确率和响应延迟作为最终依据
| 特性维度 | BGE-large-zh-v1.5 | BGE-M3 |
|---|---|---|
| 核心定位 | 中文场景性能王者,专为中文优化 | 全能型多语言模型,统一解决多语言、多功能、多粒度问题 |
| 语言支持 | 主要针对中文,在多语言场景下能力有限 | 支持超过100种语言,在多语言和跨语言检索任务中表现卓越 |
| 输入长度 | 最大 512 tokens,适用于常规段落。文本分割建议长度500 | 最大 8192 tokens,可直接处理长文档,无需分段。文本分割建议1000或以上 |
| 检索功能 | 单一稠密检索(Dense Retrieval) | 三合一检索:稠密检索、稀疏检索(Sparse)、多向量检索(Multi-Vector) |
| 技术亮点 | 基于RoBERTa架构,经大规模中文句对对比学习与指令微调,在中文语义理解上深度优化 | 通过“位置重训-大批次训练-自知识蒸馏”技术,单模型实现三种检索输出,长文档处理能力突出 |
| 模型大小 | 约1.2GB(Large版本) | Base版约1.2GB,Large版约3.4GB |
| 资源消耗 | 相对较低,推理速度较快 | 较高,尤其开启多功能或处理长文本时,需要更多计算资源 |
相似性指标
相似性指标(Similarity Metrics)是用来衡量两个嵌入向量之间 “接近程度”的数学方法。嵌入领域最核心三类相似性指标:
| 指标名称 | 核心含义 | 取值范围 | 关键特性 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| 余弦相似度(Cosine Similarity) | 衡量向量方向的相似程度,与向量长度(模)无关 | [-1, 1]- 1:完全同向(最相似)- 0:正交(无相关)- -1:完全反向(最不相似) | 只关注语义方向,忽略向量模长 | 文本嵌入、RAG 语义检索、推荐系统、跨语言匹配 | 不受向量长度影响,计算高效,适配高维嵌入 | 不考虑向量 “强度”(模长),仅反映方向相似性 |
| 欧氏距离(Euclidean Distance) | 衡量向量在 n 维空间中的直线距离 | [0, +∞)- 0:完全相同- 数值越大:越不相似 | 同时考虑向量方向与长度,符合几何直觉 | 聚类(K-Means)、异常检测、未归一化向量的相似度计算 | 直观易懂,对空间位置差异敏感 | 受向量长度影响大,高维空间区分度下降(维度灾难) |
| 点积(Dot Product) | 归一化后等价于余弦相似度;未归一化时,同时反映方向 + 向量强度 | 无固定范围(取决于向量值)- 归一化后:[-1, 1]- 未归一化:(-∞, +∞) | 计算最快,可灵活结合方向与长度 | 归一化嵌入的大规模检索、推荐系统(需结合热度 / 强度) | 计算效率最高(无开方、除法),适配向量数据库索引 | 未归一化时结果可比性差,易受向量模长干扰 |
说明:余弦相似度通用配置normalize_embeddings(向量归一化,让余弦相似度计算更准确,几乎所有场景都推荐开启)
参考资料
下载地址
实战Ollama嵌入服务
Ollama提供嵌入模型服务,可用于开发环境
BGE-M3使用
安装Ollama,然后执行下面命令
shell
# 下载 BAAI BGE-M3
ollama pull bge-m3:latest
# 查看模型
ollama list安装开发依赖
shell
pip install -U langchain-ollama -i https://mirrors.aliyun.com/pypi/simple --trusted-host=mirrors.aliyun.com基本使用
python
from langchain_ollama import OllamaEmbeddings
# 嵌入模型
embeddings = OllamaEmbeddings(model="bge-m3", base_url="http://127.0.0.1:11434")
# 单个文本
text = "hello world"
single_vector = embeddings.embed_query(text)
print(str(single_vector)[:100])
# 多个文本
texts = ["hello world", "hello python"]
vectors = embeddings.embed_documents(texts)
for vertor in vectors:
print(str(vertor)[:100])运行Ollama服务
重启后,Ollama服务可能处于关闭状态。此时无法调用bge-m3嵌入模型。打开CMD执行下面命令,运行Ollama服务
shell
# ollama ps命令,会触发启动Ollama服务
C:\Users\zlj>ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
C:\Users\zlj>说明
Ollama 官方提供的 bge-m3 模型,与原始 Hugging Face 版本相比。生产环境建议使用Hugging Face 版本。
| 能力 | Hugging Face 原版 | Ollama bge-m3 |
|---|---|---|
| Dense 向量 | ✅ 完整 + 归一化 | ✅ 有,但需手动归一化 |
| Sparse 向量 | ✅ 支持 | ❌ 不支持 |
| Multi-vector | ✅ 支持 | ❌ 不支持 |
| 8K 长文本 | ✅ 支持 | ⚠️ 可能截断 |
| 中文效果 | ✅ SOTA | ✅ 较好(但略降) |
| API 易用性 | 需部署服务 | ✅ 本地一键运行 |
实战Xinference嵌入服务
Xinference提供嵌入模型服务,可用于生产环境
安装与启动Xinference
安装与启动Xinference,参考文档:《Xinference安装与使用》
运行模型
访问Xinference 的UI界面:http://<IP>:9997/ui
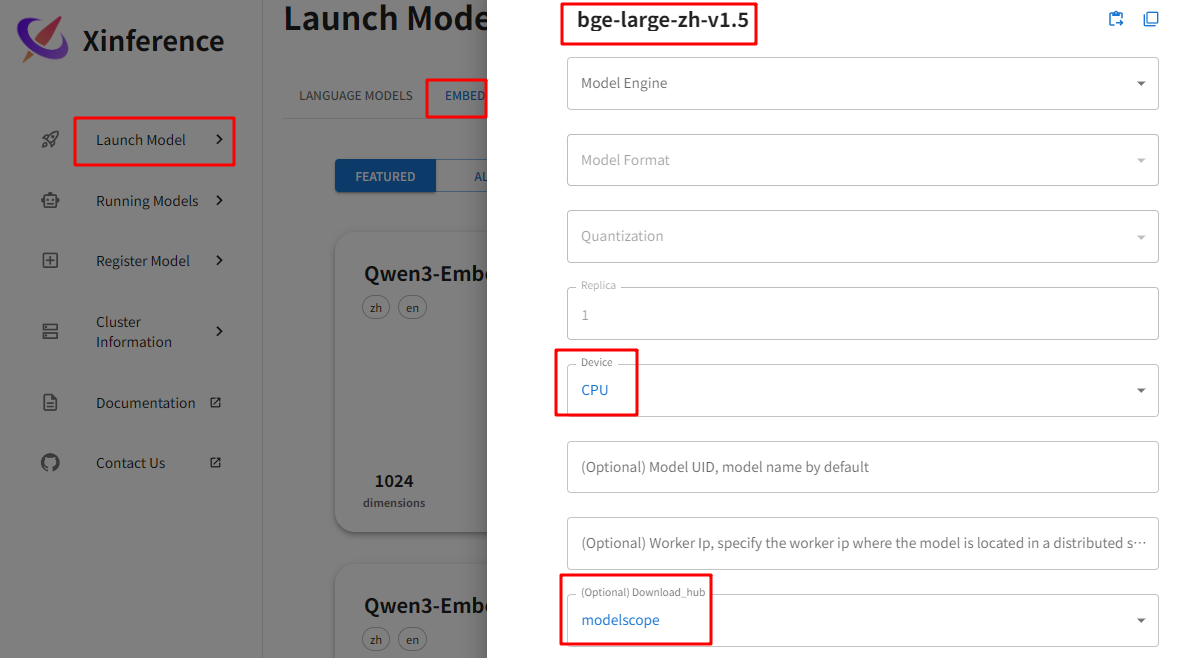
运行模型:登录Xinference界面,Launch Model -- EMBEDDING MODELS -- bge-large-zh-v1.5
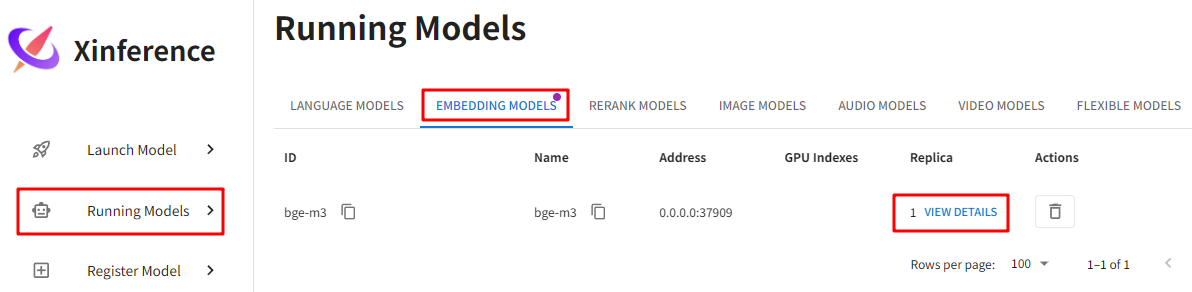
查看状态:Running Models
调用模型接口
调用embedding模型:注意修改model参数
shell
curl -X POST http://127.0.0.1:9997/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "bge-m3",
"input": ["你好,欢迎使用 Xinference"]
}'调用chat模型:注意修改model参数
shell
curl -X POST http://127.0.0.1:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "<model_uid>",
"messages": [
{"role": "user", "content": "你好,请自我介绍"}
]
}'Python SDK调用
python
from openai import OpenAI
# TODO: 替换为自己Docker的IP地址
client = OpenAI(base_url="http://172.22.62.247:9997/v1/", api_key="-")
response = client.embeddings.create(
model="bge-m3",
input="What is Deep Learning?",
)
print(response.data[0].embedding)langchain中调用
shell
from langchain_community.embeddings import XinferenceEmbeddings
xinference = XinferenceEmbeddings(
server_url="http://0.0.0.0:9997", model_uid="915845ee-2a04-11ee-8ed4-d29396a3f064"
)其它说明
- 如果使用pip来安装Xinference ,容易报错。
- 如果使用TEI(Text Embeddings Inference)容器来启动,有较多硬件限制,尝试多次未能成功。