外观
Xinference安装与使用
Xinference
介绍
Xinference(Xorbits Inference)是 Xorbits 团队开发的开源 AI 模型推理服务平台,可一站式部署和管理大语言模型、嵌入模型、多模态模型等,支持本地与分布式部署,适配多硬件与推理引擎,兼具易用性与企业级能力
| 特性 | Xinference | Ollama | BentoML/Ray Serve |
|---|---|---|---|
| 模型类型 | 全模态(LLM/Embedding/ 多模态) | 以 LLM 为主 | 需手动适配多类型 |
| 推理引擎 | 多引擎自动适配 | 单一引擎 | 需手动集成引擎 |
| 分布式部署 | 原生支持 | 有限支持 | 支持但配置复杂 |
| 企业级特性 | 权限 / 监控 / 多租户 | 基础管理 | 需二次开发 |
| 易用性 | 低代码 / 无代码 | 极简但功能有限 | 需编写部署代码 |
安装准备工作
- Windows 上安装 WSL2
- WSL2 上安装 Ubuntu 22.04
- Ubuntu 22.04 上安装Docker
参考文档:《WSL安装与使用》
安装与启动
Xinference 官方镜像已发布在 DockerHub 上的 xprobe/xinference 仓库中。
- 对于 CPU 版本,增加
-cpu后缀,如nightly-main-cpu。
shell
docker pull xprobe/xinference:v1.17.1-cpu使用镜像启动
- 指定日志级别为 debug (可选为 info )
- 挂载模型目录
shell
# 创建模型目录
mkdir -p /opt/xinference/data
docker run -d --name xinference \
-v /opt/xinference/data:/data -e XINFERENCE_HOME=/data \
-e XINFERENCE_MODEL_SRC=modelscope -p 9997:9997 xprobe/xinference:v1.17.1-cpu \
xinference-local -H 0.0.0.0 --log-level debug基本使用
可以通过下面URL访问。
http://<IP>:9997/ui使用 UI界面http://<IP>:9997/docs查看 API 文档。
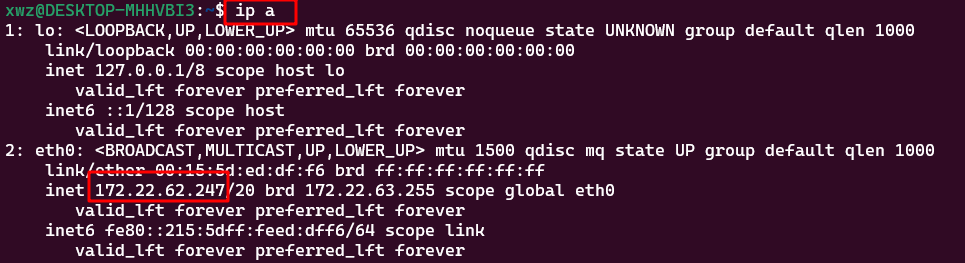
其中IP地址填写Docker宿主机的IP地址。查看IP命令:ip a
运行模型
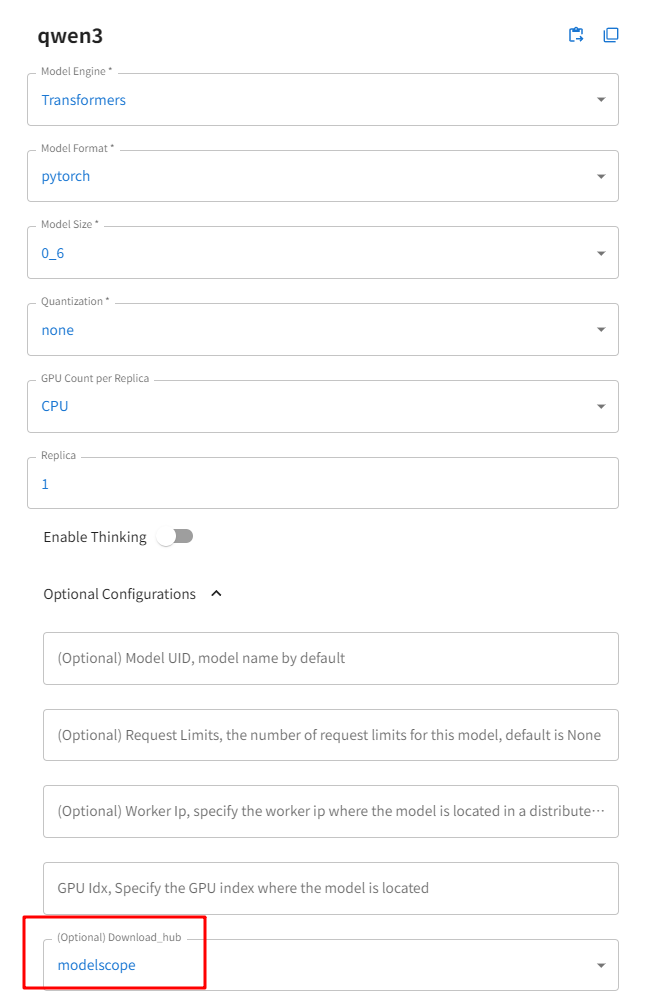
运行模型:登录Xinference界面,Launch Model -- LANGUAGE MODELS -- qwen3
参数说明:
- Model Format: 模型格式:可以选择量化和非量化的格式
- Model Size:模型的参数量大小
- Quantization:量化精度
- N-GPU:选择使用第几个GPU
- Model UID(可选):模型自定义名称,不填写模式用原始模型名称
- Download hub:选择魔塔modelscope
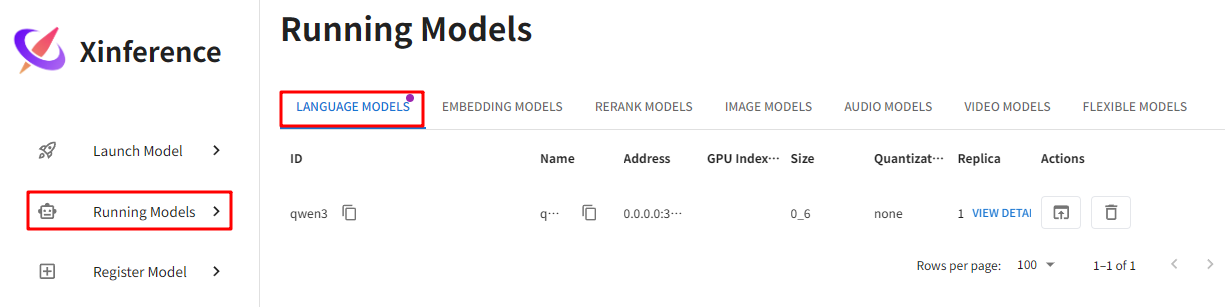
模型运行中界面:Running Models -- LANGUAGE MODELS
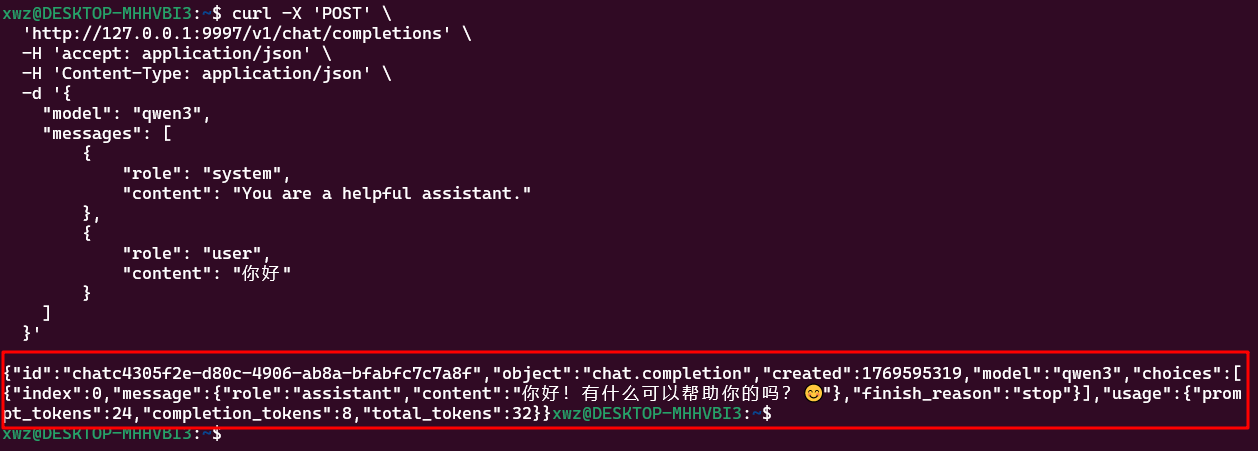
调用模型接口
查看 API 文档:http://<IP>:9997/docs
使用curl调用
shell
curl -X 'POST' \
'http://127.0.0.1:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你好"
}
]
}'调用结果示例